
Solving ARC Prize Tasks by Writing Python Code
Notes from three months of experiments

Table of Contents
Research Outcome
A History of Python Code Writing to Solve ARC AGI Tasks
Extending SOAR to ARC AGI II
Why performance was poor - reasons we DO understand
Why performance was poor - reasons we DON’T fully understand
Our competition approach
Challenges with program execution
Getting faster inference in Kaggle
The transductive filtering side-quest
Model fine-tuning notes
Experiments fine-tuning GPT-OSS
Things we didn’t get to
Open Sourcing Training Scripts and Python Program Datasets
Future Work
Research Outcome
Lewis Hemens and I spent the guts of three months trying to write python programs to solve ARC AGI II. This culminated in scoring 1.67% on the ARC AGI II semi-private evaluation set. At that point, we switched to other approaches, and I started to focus on diffusion and then TRM models as more promising directions. You can read more here about our TRM post-training approach, which scored 6.67% on the semi-private eval set.
A History of Python Code Writing to Solve ARC AGI Tasks
In mid 2024, Ryan Greenblatt provided a canonical example of using LLMs to write python programs that solve ARC AGI tasks. He used GPT-4o and reached ~50% on the ARC AGI I benchmark. Simply put, Greenblatt passed task descriptions to the LLM and had it write a python program solution to all training tasks. If correct on training tasks, the program would be rolled out to make a test output prediction. Greenblatt also allowed wrong programs to be fixed by the LLM (aka “refinement”), further improving accuracy. A key requirement for high performance was sampling a very large number (thousands) of programs per task, because performance roughly increases with the logarithm of samples (until hitting an asymptote).
Pourcel et al. took the python program writing approach further in their SOAR paper, notably by:
Fine-tuning open source LLMs of various sizes on correct programs.
Fine-tuning on wrong programs using canonical grid inputs BUT using output grids produced by the model rather than the ground truth outputs. This has become known as “hindsight relabelling” or “relabelling”. In Guillermo Barbadillo’s 2025 ARC report, he shows a nice example of teaching a model to draw using this kind of relabelling technique and finds some improvement on ARC AGI I tasks with relabelling.
The SOAR approach can be loosely summarised as:
Iteratively sampling and fine-tuning on ARC AGI I training dataset programs (including on traces for fixing draft programs, called “refinements”), followed by
iteratively sampling programs solving train examples from the test set and then fine-tuning on those programs (although no training is done on refinements of test programs), followed by finally
producing test grid outputs through majority voting based on train grid correctness.
When ensembling open source models subjected to this approach (ranging from 7B up to 123B parameters), SOAR exceeds 55% on ARC AGI I public evaluation set.
Eric Peng (writing python programs) and Jeremy Berman (writing natural language programs - not possible with models weaker than Grok 4) went further and scored in the high 20s on ARC AGI II public evaluation tasks. They added more complex sampling and refinement loops, but also used a strong reasoning model, Grok 4. Note that python writing approaches until that point were not done with reasoning models, and the SOAR fine-tuned approach does not even have a chain of thought involved in program generation.
Extending SOAR to ARC AGI II
Our basic research premise was to take the SOAR paper and try to apply it to ARC AGI II. Initially, we thought this would mean:
Generate a dataset of python programs and program refinements (correct, partially correct and incorrect on train and test examples) for ARC AGI II training data [with the later plan of also doing so for the public evaluation set, to try and juice our model, but losing the ability to run an independent evaluation]. The basis for this dataset was the SOAR dataset that covers ARC AGI I training tasks. To enhance the SOAR dataset to cover all ARC AGI II training tasks, we ran thousands of dollars of inference, via OpenRouter, on strong models such as GPT-5-mini, GPT-5 and Gemini Flash and Pro.
Train a base model - perhaps Qwen 3 4B or 8B (hoping to get a boost over the Qwen 2.5 model used in the SOAR paper) on that dataset.
During the Kaggle submission:
Sample ~128-512 programs per task.
Fine-tune on correct, relabelled partially correct and maybe relabelled incorrect programs.
Run sampling again for 128-512x samples per task and then do majority voting over all 256 samples per task to get final grid outputs to submit.
This didn’t work well - for reasons we now understand and for reasons we still don’t fully understand.
Why performance was poor - reasons we DO understand
After lots of sampling to generate pre-training data, we had near zero programs for tasks that were of ARC AGI II evaluation difficulty
ARC AGI II evaluation tasks are much harder than ARC AGI I tasks (training and evaluation) and ARC AGI II training tasks. Of the 120 ARC AGI II evaluations tasks, after sampling with the strongest models, we only had fully correct (correct on train and test examples) programs for 8 out of 120 tasks! [We did not sample much with Grok 4, as our work was prior to its release.]
Even for the hardest tasks in the ARC AGI II training split (which we filtered by giving GPT-5-mini roughly eight attempts at solving), we were able to find correct solutions for only 50 out of 137.
And so, one cannot rule out the hypothesis that our SOAR approach on ARC AGI II was weak because we didn’t have the programs for hard enough tasks (and it is not obvious how one might get them!).

We could not get refinement to work on ARC AGI II
In a conversation with Julien Pourcel of the SOAR paper, he shared that using larger stronger models (e.g. larger than Qwen 2.5 14B) was required to get refinement to work for ARC AGI I.
Throughout our research, the way we assessed refinement (i.e. feeding a draft program for the LLM to improve on) was to compare it to a baseline of additional sampling for the same number of iterations. For ARC AGI II tasks, we were never able to do better by refining programs than by just sampling more.
We also realised that refinement was less interesting for ARC Prize submissions because compute is constrained and it’s not worth refining until you saturate sampling. Concretely, as you sample more programs for the same task, performance goes up roughly with the log of samples. This does eventually asymptote. The point at which the slope of the sampling curve falls below the slope of doing refinements is where refinement becomes worthwhile, but this is at quite a high level of sampling, probably in the hundreds or thousands of samples per task, and you cannot generate that many samples with a 4B model - even in FP8 - on 4xL4 in 12 hours.
You can’t easily see it on the graphs below from the SOAR paper - because the x-axis is log, and you need to compare slopes on a linear graph - but, what you can see is that, if you sample a lot, the additional boost from refinement is not all that large. Scan your eye to the right of the Mistral-Large plot and you can see a boost of only a few percent if you have already exhausted pre-training and test-time tuning (dark red curve).
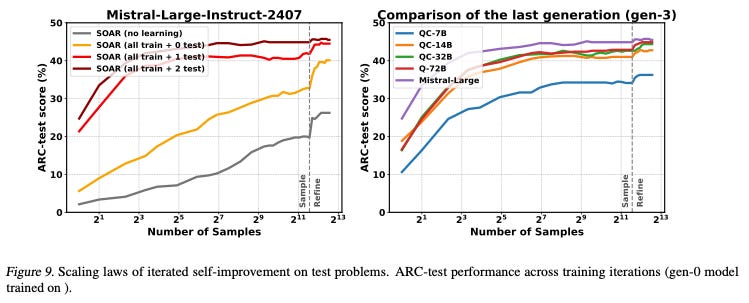
Test-time tuning was not useful in a compute constrained environment
Originally our submission plan was to sample with a pre-trained model, do test time fine tuning, and then sample some more. For a similar reason to refinements, we realised that doing test-time fine-tuning is less useful in a compute constrained environment. One is possibly better off doing more sampling on the base model, than doing test time tuning.
If your head is in the mindset of test time training from the 2024 Prize winning submission, or in the framework of test-time fine-tuning on a Tiny Recursive Model, then test-time training seems obvious for writing python programs too. However, the context is different because writing python programs involves an inductive approach (you write a program to then execute and generate the answer), while the 2024 vanilla transformer and 2025 TRM approaches are transductive (you directly predict output grids). The difference, when it comes to test-time tuning is that:
In transductive approaches, the data is ready once you enter the competition environment. You can immediately train on the test set train examples.
In inductive (e.g. python) approaches, the data is the programs, and you first need to need to generate those for the unseen train examples when you enter the competition environment. So, you have a lot of work/sampling to do before you can start the tuning step.
Worse, while it looks like iterations of test time tuning are very powerful (see 0 vs 1 vs 2 iterations of test time tuning on evaluation train examples in Fig. 9 above), the improvement seen is coming largely from sampling, not test time tuning. This is a subtle point. Concretely, at 2^5 samples, Mistral large scores 26% (yellow curve) after pre-training. After one round of test-time tuning, on programs drawn from 3,000 samples and 3,000 refinement samples, the score goes up to ~41%, a large increase. This is misleading. Although we are at 2^5 (32) samples on the x-axis, all test-time fine-tuning (irrespective of x axis position) is done with 6k samples (half of which are refinements). As such, most of the boost in performance is because of test-time tuning on data pulled from a very large sample set (not from 32 samples!). For a more representative estimate of the “pure” test-time boost, one might consider the red curve at a given level of sampling with the yellow curve at the highest level of sampling. Measured in this way, the boost provided by test-time tuning is much smaller.
As with refinement, when compute is limited, one is nearly always better off sampling for longer than spending compute trying to fine-tune on those samples and resample with the fine-tuned model. Add to this the fact that test-time tuning is helpful to the extent the original model generates correct or somewhat correct programs. ARC AGI II is so hard that a first pass of sampling generates few correct programs, and there is little boost to be had for tuning on those examples. I comment more on this below in the section on incorrect programs. Note that when we say “incorrect programs” we typically mean programs that predict valid output grids (i.e. 30x30 or smaller) that are wrong. Programs that fail to execute or produce grids of invalid size or with invalid colours are discarded and would never be used for training.
One last perspective on test-time tuning for inductive approaches: Doing test-time tuning does improve the model on a pass@1 basis, but it is hard to get much improvement in pass@1000 (or pass@ any other high number). Essentially, test time tuning makes rare correct answers more common. From a pre-training perspective, this is useful, because it makes your model more accurate at competition time. But from a competition perspective, if you have to expend compute sampling, then you already have the rare answers (so just use those directly!), and you are mostly wasting compute by test-time tuning to bake those those correct answers into a fine-tuned model.
Why performance was poor - reasons we DON’T fully understand
We did not get a clear signal that hindsight relabelling helped
SOAR trains on a blend of correct programs, relabelled partially correct (i.e. gets at least one train or test example correct) and even relabelled incorrect programs. We were always interested in the question of whether training on partially or fully incorrect programs could help and why, especially because the SOAR paper reported relatively small differences when varying the data mix.
We ran rough ablations across three mixes, all correct, all+partial and mixed correct plus incorrect. It was difficult to find a clear signal on which was best because:
a) There is a large amount of noise in comparing runs. One needs very many samples per task, perhaps thousands, to get statistical significance for a given run.
b) It was hard to disentangle the benefits of just training on more data versus training on the different data mixes. This is particularly true because the number of correct versus partially correct vs incorrect programs we had per task is, as one might expect, very non-uniform. Indeed, many tasks had zero all correct programs and some had none even partially correct. So, even if you hold constant the size of the training set, it is hard or impossible to hold constant the shape of the distribution.
We did some manual inspection of fully incorrect programs, as well as partially incorrect, and they rarely seemed to be representative of ARC tasks. This reinforced our skepticism on the utility of training on incorrect programs and perhaps even partially correct programs. It’s worth mentioning that - from a data management perspective - it is useful to drop incorrect programs, which are the bulk of programs generated and clearly are not of the highest quality.
It is hard to describe certain ARC tasks with python programs
There are tasks - perhaps those involving quite irregular shapes - where it is easier to describe the transformation in words than to do so precisely with a python program that is forced to operate on a pixel level. While not having any direct evidence of this, our failure to generate correct python programs, even with strong reasoning models, perhaps pointed in that direction.
One counterargument is that Eric Peng achieved close to 30% on ARC AGI II using Grok 4 to write python programs. The counter-counterargument is that perhaps he would have scored higher were all tasks suited to python programs. The counter-counter-counterargument is that Jeremy Berman also scored almost 30% with a natural language program approach, so perhaps it’s not python that’s the limit after all?
Side-note: Lewis took the time to solve an ARC AGI II evaluation program by hand, and found that exceedingly difficult, much harder than solving on the arc website by clicking.
Our competition approach
Originally we ran a flow of sampling, fine-tuning and more sampling in Kaggle. In that flow, 90%+ of the time was spent on sampling. This is because ARC AGI II semi-private tasks are so hard that few programs would pass execution and produce valid sized output grids. This meant relatively few rows to fine-tune on (~100s), which made for a fast fine-tuning.
Once we realised test-time tuning was not helpful, we moved to running only sampling on the pre-trained model during competition time, using as many samples as possible in the 12 hours allowed.
As a rough proxy for task difficulty, we would sort the tasks from shortest to longest, with the idea of trying to tackle the easiest ones first. We considered other dynamic strategies, like moving on from a task once we reached 5 all correct programs on train examples OR ditching a task if we had zero partially correct programs after 256 attempts. Ultimately we did not ablate this much because our baseline performance was too low for it to warrant attention.
Challenges with program execution
Unexpectedly, one of the biggest pain points of the python approach was executing python programs. The issue is that one does not know - in advance of execution - whether programs might explode memory or run in an infinite loop. While timeouts can be used to manage infinite loops, the problem of memory management proved a lot more challenging. We tried to kill processes if certain memory thresholds were exceeded, but this was hard to do in practice when trying parallelise program execution. We never full solved program execution and the task runner would fail unexpectedly in pre-training and during submissions.
In a brief exchange with Eric Peng regarding his python-writing approach with Grok 4, he shared similar challenges with trying to build a robust python program execution environment.
Getting faster inference in Kaggle
We were able to significantly increase the number of samples per task using Qwen 3 4B and 8B models by leveraging FP8 formats. L4s (Lovelace architecture) provide support for FP8 and we found that - by quantising our pre-trained models to FP8 using LLM Compressor - we were able to roughly double inference speed while maintaining quality. Actually our highest score of 1.67% on the semi-private set was achieved just by making an FP8 version of the SOAR Qwen 14B model (now released here) and running it for 64 attempts per task and 32 refinements per task. We also used kv-cache quantisation with `--kv-cache-dtype fp8_e4m3`.
We ran inference using data parallel with SGLang across the four L4 GPUs, although later we saw inference test results suggesting that data parallel was slower than running four replicas of the model and routing requests (which should not be the case, but we did not have time to dig further).
The transductive filtering side-quest
Something we realised quite early on - and probably spent too much time on - was that many (~5-20%) python programs produced are a trivial program with hard-coded output values for the grids. In the worst cases, programs might include mappings to hard code a specific output grid for a given input grid. Such programs run successfully and may score 100% on train examples, but typically don’t generalise to test examples.
The SOAR paper aims to mitigate this by filtering out programs where output grids are directly hardcoded. However, what we saw was that the hardcoding of outputs (what we called “transductive programs”) was more grey than black and white. For example, some programs might hard code outputs in separate blocks that a simple regex filter would not capture.
We quickly tested whether LLMs or embedding models could be helpful in detecting transductive programs, but found they were not. In the end, Lewis built a small feature-based classifier with reasonable precision recall scores, and we used that classifier to filter out transductive programs both from training and from voting (technically, we down-weighted transductive examples, because sometimes they can lead to correct answers).
The code for that classifier is included in the ARC AGI 2025 repo we have open-sourced. (We recommend using Codex or Claude Code to explore the repo.)
Model fine-tuning notes
To avoid the complexity of multi-gpu training, we stuck to using a single large GPU, often a B200 or H200 using Unsloth. Originally we trained with a cosine schedule for three epochs, as done in the SOAR paper, but then moved to two epochs with a constant schedule for simplicity. We used shared data preparation utilities for preparing prompts, whether for inference or for fine-tuning, and we used a Jupyter notebook for fine-tuning. All scripts are available in the repo below that has been open sourced. Depending on the amount of data, we ran pre-training runs that spanned anywhere from 2 hours up to 48 hours.
Experiments fine-tuning GPT-OSS
For most of our research we made use of Qwen 3 models as they were the strongest available small and open source models, at least until the release of GPT-OSS. While GPT-OSS-120B fits into 4xL4s in principle, the inference is too slow and too few programs can be sampled in twelve hours to be useful. GPT-OSS-20B is more interesting because one can fit a copy on every L4 (i.e. run four in parallel) AND inference is faster than Qwen 3 4B, while the base model is more powerful.
However, the release of OSS was towards the end of our efforts on python program writing and we did not devote significant effort to it. The efforts we did spend were largely spent on:
a) Trying to fine-tune OSS-20B with reasoning traces (gathered from Gemini Flash and GPT-5-mini).
b) Briefly trying to replicate the Jeremy Berman approach of writing natural language python programs.
The OSS-20B model proved to be a lot less stable than expected when we fed in ARC AGI tasks with multiple examples. With longer context inputs, the output was often malformed, and many evaluation runs had over 50% of attempts generate no valid programs (compared to no more than 10% or less on Qwen 3 models, whether fine-tuned or not).
While it was possible to write and execute natural language programs using OSS-20B on easy ARC AGI I tasks, this did not scale to ARC AGI II - very much as Jeremy had advised in our conversations.
Throughout our research, we did not give any consideration to reinforcement learning (in the GRPO, PPO, etc. contrastive sense) because we felt such optimisations were unlikely to bring about a benefit if we could not first get reinforcement learning through verification, filtering and supervised fine-tuning to work. Plus, the rewards for solving ARC tasks are quite sparse. There is a gulf between programs that output valid grids of the right size to those that get at least one training example correct, and there is no obvious way to assign a reward in between. We put some thought to distance metrics put not enough to come up with anything better than pixel match as a crude proxy. [Note that reward sparsity is as much a problem for doing RL via SFT as via something like GRPO, it’s just the problem manifests in the filtering strategy rather than the reward definition.]
Things we didn’t get to
Had we seen more promise in extending the SOAR approach from ARC AGI I to ARC AGI II evaluation tasks (e.g. scoring even 3-7% on the semi-private dataset), our plan was to further improve by compounding new programs from existing programs, as well as decomposing existing programs into component programs. This was our motivation to pursue the python approach from the beginning.
Compounding new programs
The idea for compounding programs is simple. Take two python programs that correctly solve different ARC tasks, and ask an LLM to combine them to form a new program. This is harder than it sounds - not just because the LLM struggles to compound an “ARC-like” new program - but because there is the joint problem of needing to define not just the transformation but also a input grid (or set of input grids).
As a first step, we held input grids fixed and tried to compound a program for a given task with a program solving another randomly chosen task. A small ablation on just a few thousand programs failed to lift performance more than training on a baseline set of original programs. To properly ablate this kind of improvement, one needs to think harder about a suitable baseline fine-tuning case. It’s easy - through a variety of methods - to improve a base model through fine-tuning. The relevant question is whether fine-tuning on compounded programs can improve on an already strong fine-tuned model.
Decomposing tasks
We did not try to do this and don’t know how it would be done. The broad idea is to take difficult python programs and try to have an LLM split them into component tasks. This is again harder than it sounds because splitting a python program gives no guarantee that the intermediate state is a meaningful ARC grid. Perhaps it need not be?
If composing and de-composing tasks were possible, not only could it benefit a SOAR type approach, but the composed and de-composed tasks could be used to train arbitrary approaches to ARC.
Making manual tasks
Given we could not solve many ARC AGI II evaluation tasks, one thought was to train the model on simpler versions of those tasks, just by creating tasks manually. A simple html application was vibe coded to create new tasks and export them in ARC format. Roughly two dozen such tasks, capturing primitive concepts in some ARC AGI II evaluation tasks, were created and are available in the “manual” dataset in the data folder in the shared repository.
Open Sourcing Training Scripts and Python Program Datasets
We have open sourced our repository and also three datasets (HuggingFace collection here) with python programs and reasoning traces for solving ARC tasks. We have also included an FP8 version of the SOAR 14B model.
Future Work
The obvious - but not easy - thing to do is to manually write or wait for stronger LLMs to write programs that solve ARC AGI II difficulty tasks. Even if pre-training on those examples worked, it would be unsatisfying because of the reliance on a strong teacher. Really, what is desired is proving that it is possible to hill climb from a weaker model to a stronger model by only interacting with the training data and train examples from the evaluation tasks. This points towards thinking more about how to better compound and decompose programs, with the aim of showing that a model can latch on to simpler programs, and from there reach more difficult programs. Depending on how superficial an LLMs understanding of programs is (itself a worthwhile pursuit), this may or may not be possible.
It is interesting to note how augmentation strategies (rotate, flip, recolor) have performed well in the 2024 competition and also when mixed with Tiny Recursive Models. Meanwhile, these augmentations have not widely been used in inductive approaches - as far as we know. We noticed python programs that correctly solve all examples for a task are only sometimes invariant to flips, re-colours and rotations, suggesting such augmentations may help in training.
Zooming out - for this python approach, or for any ARC approach - a fundamental question remains around what size pre-training-optimal and competition-inference-optimal models are to solve ARC AGI II. Today, approaches span from 100M to 10B+ parameters. Perhaps narrowing down that range (if indeed the optimum is within that range) offers room for improvement, and, might bias the approach towards or away from one that requires core knowledge of python or indeed any domain specific language.
Acknowledgements
Thanks to Julien Pourcel and Jeremy Berman for discussions on their approaches. Thanks also to Runpod for substantial support providing compute credits. For bonus credits on sign-up, use this Runpod affiliate link here.