
GRPO is Poor and for the GPU-Rich
And what you can do about it

A specific GRPO vs SFT video will be out next week, but I'm putting initial results here. Subscribe on YouTube and turn on notifications to be first notified when it releases.
I trained Llama 3.2 1B on GSM8K with:
1. SFT
2. ORPO
3. GRPO
For SFT and ORPO, I generated training data using Llama 3.2 1B by taking 8x samples per training problem and retaining only those that are correct (as well as some incorrect for ORPO pairs).
For GRPO I also set sampling to 8x per training example.
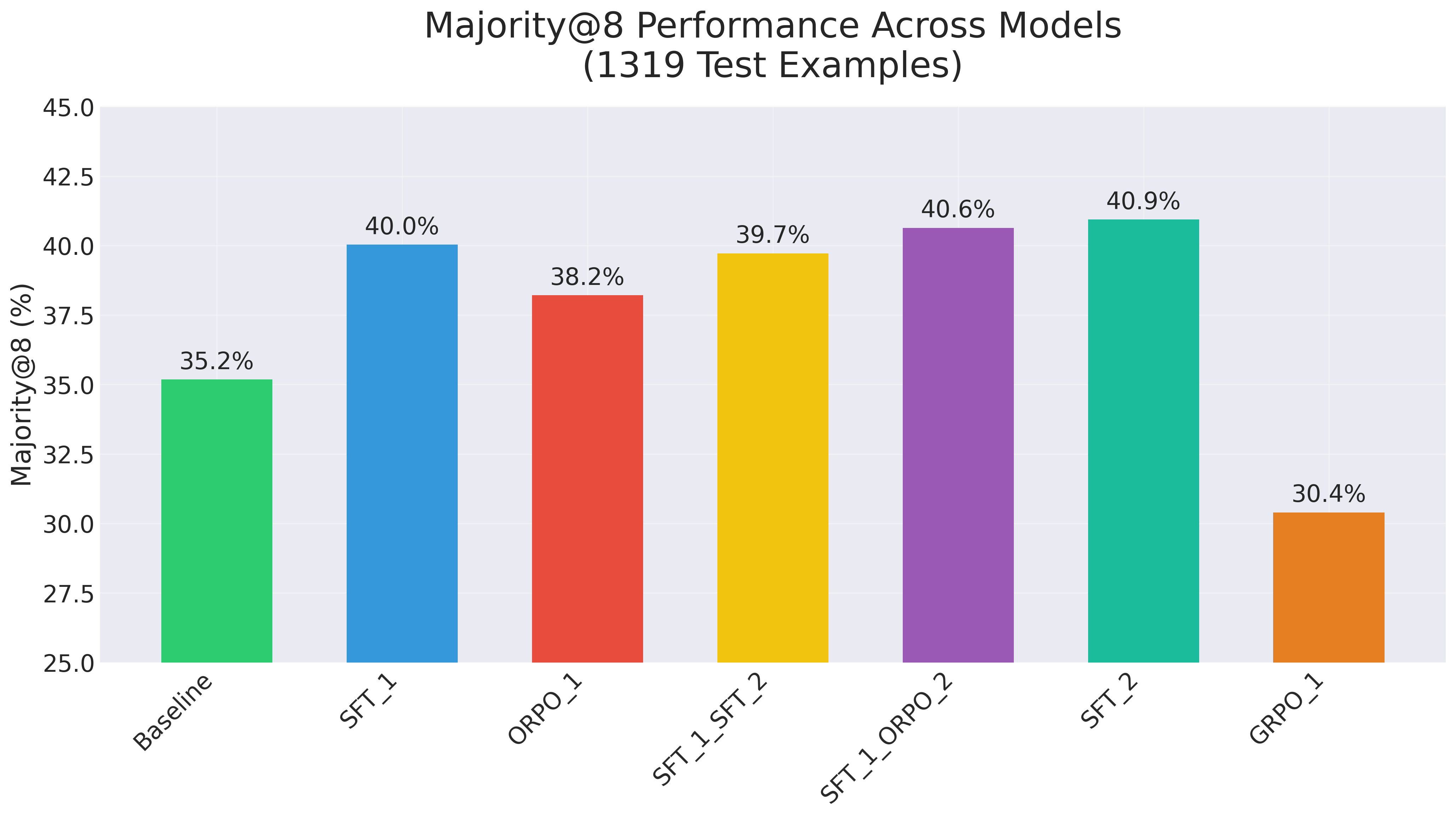
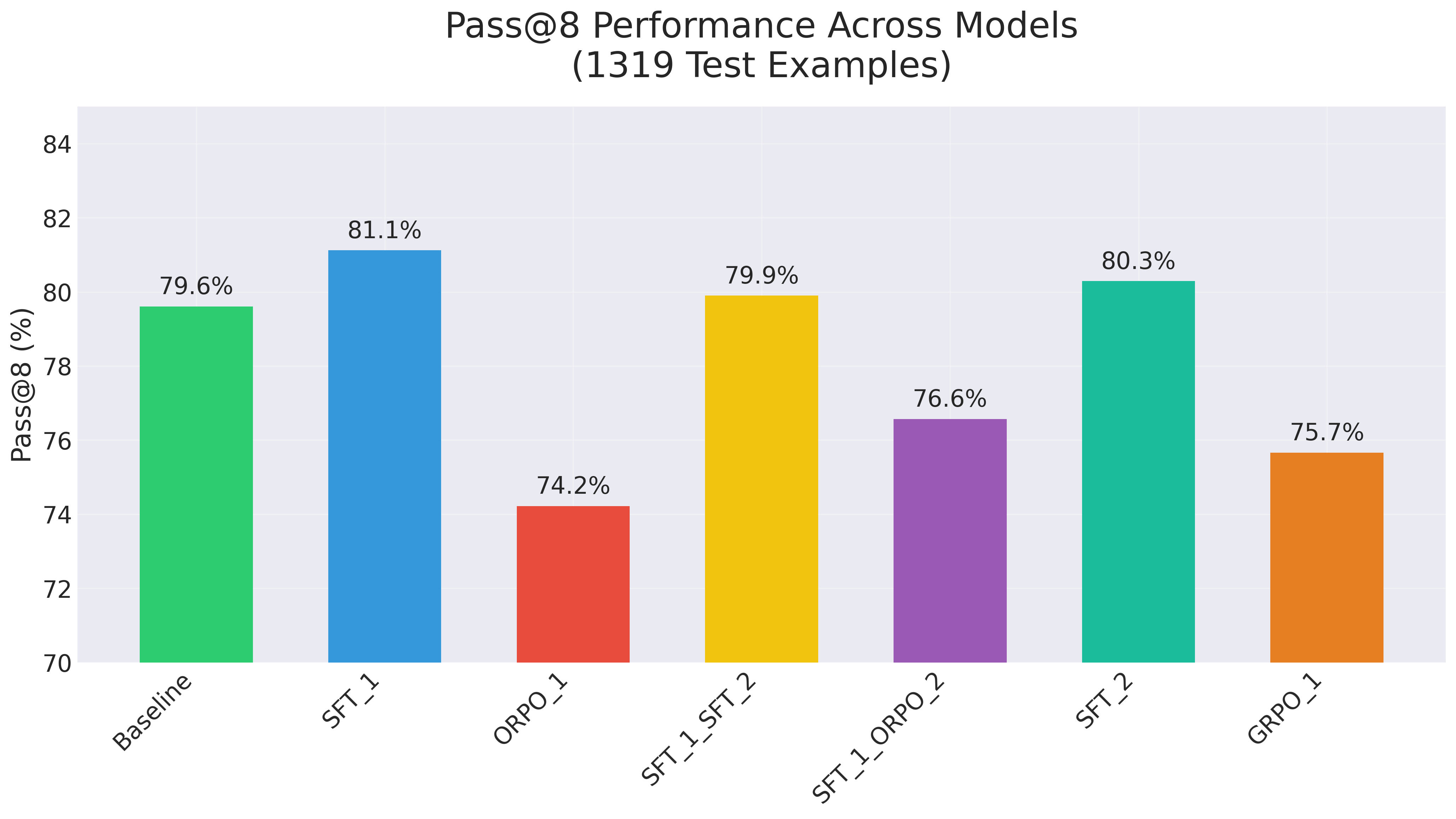
1. SFT_1 is one round of fine-tuning on correct answers filtered from sampling.
2. ORPO_1 is one round of ORPO on correct-incorrect pairs from sampling.
3. SFT_1_SFT_2 takes the SFT_1 model to generate 8x samples per training row (and these are better samples!), and then uses those samples to do a second round of SFT.
4. SFT_1_ORPO_2 does the same as #3 but uses ORPO pairs for the second round.
5. SFT_2 is one round of SFT but on verified results sampled from the SFT_1 model (which are higher quality).
6. GRPO does 8x sampling and uses reward functions for correctness and format. GRPO was run past toward reward flatlining (which was about 3k rows of training data, out of 7k max available). {Side note: SFT on data sampled from a few thousand rows shows an improvement.}
In short:
1. Nothing improves pass@k by much. Basically, whatever answers the model can reach, the base instruct model can already reach.
2. SFT and ORPO improve maj@k, which is the percentage of test examples that are right in 5/8 or more cases. Note: if you're only measuring single attempt performance (pass@1), performance will improve, but it is because maj@k improves, not because pass@k is improving.
3. GRPO makes pass@k and maj@k worse in this case. I'm not saying that necessarily generalises. Most likely GRPO is improving formatting at the expense of correctness [See graph attached for tensor board logs of correctness and formatting rewards. Formatting indeed improves, correctness improves but that encompasses correctness because of formatting imrpovements].
Why does GRPO seem to improve performance in a lot of quick tests?
It’s measurement nuance…
You can get a lot of apparent improvement in correctness just through formatting improvements. Once you impose a format requirement, answers that were correct are marked wrong (making the start of RL look bad). As formatting improves through RL (whatever the method), this results in more answers being marked correct, and so you see an apparent improvement. [Once you mitigate this by using multiple correctness checks, including output vs ground truth checks using LLM as judge, this source of improvement goes away].
Why does GRPO work for DeepSeek?
- I don't entirely know.
- One hypothesis is that DeepSeek v3 is just bigger and more powerful, and has base pre-training patterns engrained that allow improved answers to be iteratively elicited.
- Another (not mutually exclusive) hypothesis is that the breadth of learning in RL is quite narrow, i.e. you can make a model (provided big enough) recursively improve provided the domain is sufficiently narrow and the model has encoded relevant pre-training data. Essentially, once you have defined a benchmark for an LLM, it's possible to perform well on a benchmark (given a large enough model and sufficient training examples - although generating training examples may not be trivial). This idea is somewhat supported by an earlier RL paper with Ilya on it where it was necessary to pre-train on a large maths split before getting outcome and process rewards models to achieve improvements.
What should the GPU-poor do?
1. Use the strongest available model to generate reasoning answers
2. Verify and keep the correct answers
3. Do SFT on those correct answers
See this video from last week:
There are now a few directions of evidence for why simple SFT on strong answers makes sense:
a. Deepseek's R1 paper explicitly says that smaller models were stronger when trained on traces from bigger models than when they underwent RL themselves.
b. The recent s1 paper from Stanford shows that having traces from a strong model + SFT can result in large (in domain) reasoning boosts.
What if R1 is bad at your dataset/application?
- Probably still you should sample R1 (or another reasoning model that reveals traces) and use verified samples for SFT.
- Doing loops of RL is best when there are no existing models that can reach correct answers (and, as you can see from these graphs, with weaker models, you may not be able to recursively improve and increase pass@k). If you want to push the frontier, possibly your base model needs a lot of pre-training data for that domain AND/OR you need to do domain-specific pre-training.
Should DeepSeek have just done SFT with rejection sampling?
GRPO is quite sparse as a reward if you just look at correctness and format (which the DeepSeek paper says). This sparsity makes it wasteful (because many backward passes may not have any signal, particularly for harder problems), and the use of multiple summed rewards can result the model focusing more on one than the other (perhaps what is happening above).
So, if DeepSeek could elicit improvements via format+correctness on GRPO, I'm guessing they could have done so via rejection sampling and SFT. With SFT you can be very sample efficient - whether that's with SFT or ORPO (or the backprop part of GRPO).
Granted - and thanks to @willccbb for chatting a little on this - perhaps you can make the rewards functions more continuous with LLMs and other tools and kind of "guide" the model to better answers. Perhaps this is what o1/3 is doing.
That's it, the video will post next week - and you can get notified either here or if you find Trelis Research on YouTube or Substack.
Well done to Will Brown, Unsloth and HuggingFace for the nice work on GRPO scripts/libraries.
Cheers, Ronan
Trelis Research
Build & Deploy Faster: Fine-tuning, Inference, Audio, Evals and Vision Tools
Need AI Guidance? Book a Consultation for Technical or Market Insights
Are you a top developer? Apply to join the Trelis Team
Starting a new project or venture? Apply for a Trelis Grant
P.S. The definition of GRPO includes sampling, which is confusing because ORPO and DPO don't (PPO does, but the "sampling" is represented via a model). It's more clear (although a bit imprecise) if we describe the comparison as rejection sampling + GRPO vs rejection sampling + SFT vs rejection sampling + ORPO/DPO.